Scrape Data ke Real Website
Hai...ketemu lagi dengan gue ya... kali ini yang kita bahas masih berhubungan dengan requests dan Beautifulsoup kok... tentunya dalam rangka belajar scrape bareng oke.....
Kali ini kita coba mengambil data website https://quotes.toscrape.com/
Didalam website tersebut terdapat isi Quotes atau kata-kata dari beberapa ilmuan kita akan coba mengambil salah satu quotes dan author dari website tersebut tanpa copy paste yaa.....
Tapi dengan cara menggunakan Requests dalam program python kita boleh kita coba dalam VS code kita yaa...
Kalau kalian belum menginstall requests dan beautifulsoup4 silakan install dulu ya caranya disini
Oke disana sudah dijelaskan dah cara install requests dan beautifulsoup nya mulai dari yang pakai windows dan yang pakai linux oke...
Selanjutnya kita mulai pengambilan datanya ya...
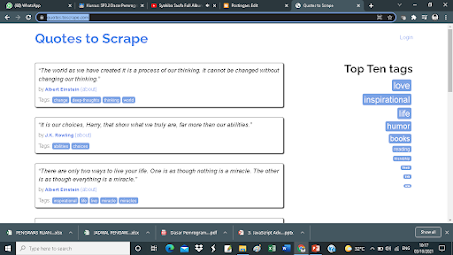
kita buka dulu websitenya nanti muncul
Nah kita akan mencoba mengambil salah satu quotes tersebut yaa beserta yang menyampaikan wuotes tersebut (authornya)
Kita instpect ya klik aja klik kanan terus ada inspect nah pasti muncul htmlnya oke..
selanjutnya html tersebut yang akan menjadi terget pengambilan datanya yang nantinya kita gunakan dalam program python kita selanjutnya kita buka VS code kita oke
dalam program tersebut dituliskan syntaknya seperti ini
from bs4 import BeautifulSoup
import requests
html = requests.get('https://quotes.toscrape.com')
html_soup = BeautifulSoup(html.content,'html.parser')
quote = html_soup.find('span', class_ = 'text').text
author = html_soup.find('small', class_ = 'author').text
print(quote)
print(author)
Jadi kita mengunakan perintah seperti diatas.. bisa kita perhatikan dalam syntak tersebut terdapat request.get
Itu merupakan target yang nantinya akan kita ambil datanya jadi dalam kurung tersebut kita copy kan alamat website yang akan kita ambil datanya. jadi setelah kita sudah tahu alamat website yang akan kita ambil datanya kita sekarang harus mengetahui juga syntak yang akan kita ambil datanya dimana bisa kita lihat di html website tersebut yan tadinya kita instpect disitu kita akan mengambil data quotenya dan author nya jadi kita cari syntak dalam inspect tadi class nya seperti apa kita samakan.
setelah semua itu dilakukan kita akan mendapat hasil seperti ini
Jadi itu hasil dari scrape data dari website yang kita mulai tadi tapi harus ingat karna kita menggunakan perintah get maka data yang diambil adalah data yang paling atas sendiri....
Sekian keterangannya yaa... masih banyak yang harus kita dalami lagi kalau ada kesalahan dalam keterangannya jangan lupa komentarnya yaa.. saya juga masih belajar kok..
"Manusia tidak lepas dari salah dan luput"